SUNY New Paltz 2017
GPA: 3.5

Take a look at my recent work! Click on any project to learn more.
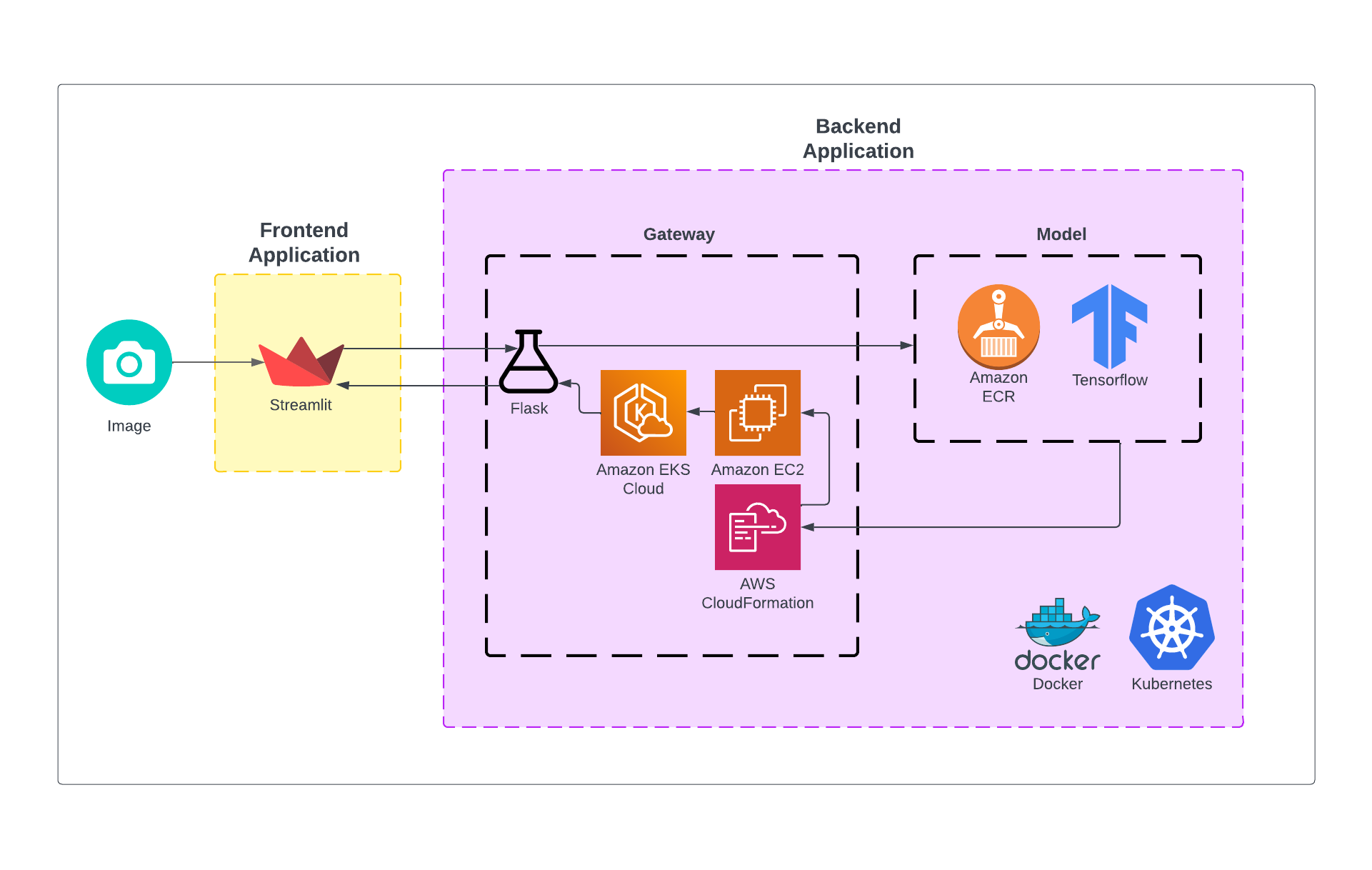
End-to-end deep learning project for dog breed image classification. Exploratory data analysis (EDA), transfer learning with keras, fine-tuning, and model deployment with flask and docker to Amazon Web Services (AWS) Lambda and Elastic Kubernetes Service (EKS), application deployment to Streamlit.

Credit prediction modeling project using scikit-learn decision tree, KNN, SVM and neural network models to forecast credit default likelihood. Data preparation, EDA, model training and fine-tuning. Deployment with SVM utilizing flask connection and environment containerization with Docker.

Built a GNN architecture using PyTorch Geometric for node classification of the protein-protein interaction (PPI) dataset. Used a combination of Molecular Fingerprint Convolution (MFConv) and Graph Isomorphism Network (GIN) layers, resulting in an F1 score within 5 points of the benchmark while reducing runtime by 67%.
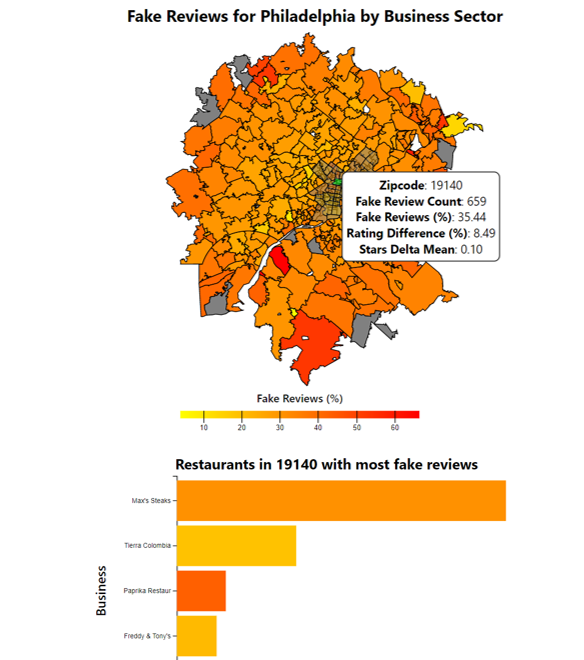
Tested SVM, KNN, naive bayes, logistic regression, and random forest classifiers to predict the presence of fake reviews in the Kaggle Yelp dataset. Used TF-IDF for sentiment analysis and oversampling with SMOTE, noting a 12% increase in recall. Developed an interactive visualization with D3 as an analytical tool to uncover sectors negatively impacted by fake reviews in suburban populations.
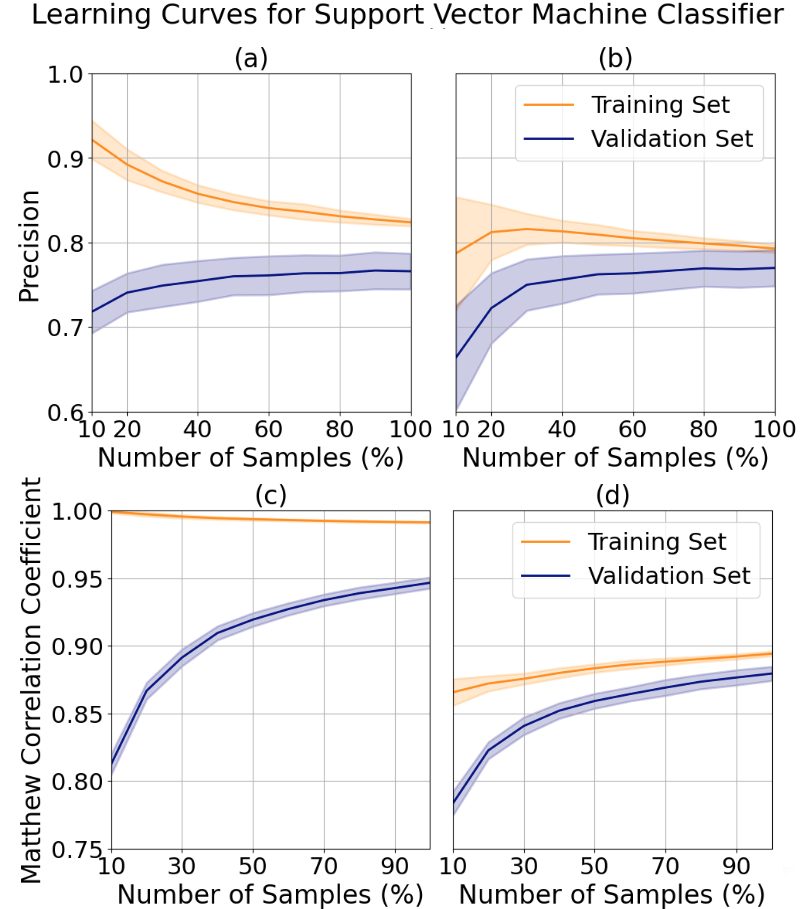
Researched the comparative strengths of decision trees, KNN, SVM and neural networks using validation curves, learning curves, wall-clock time and loss curves. Compared tuned performance for the bioresponse dataset, a wide, balanced binary classification problem, to the letter dataset, a long and unbalanced multilabel problem.
SUNY New Paltz 2017
GPA: 3.5
Grid Logistics
June 2018 - March 2020
Anchor QEA
March 2020 - August 2022
Georgia Institute of Technology
August 2022 - Present
GPA: 4.0
Since you're here, let's start with a few interesting things about me. I love listening to music and sharing good tunes with friends. You can usually catch me jamming out to electronic, RnB, post-hardcore or J-pop. In my free time, I'm an avid gamer and anime enthusiast (anything shonen is my favorite!). And last but not least, I'm genuinely obsessed with learning. Every day, I challenge myself to explore new horizons, whether it's immersing myself in the latest cloud technologies, diving into the ever-evolving world of machine learning, or even just geeking out over facts about how our planet works.
I'm a motivated graduate student with a passion for data and a proven track record of delivering impactful solutions. You'll often find me captivated by the smallest details, building meaningful visualizations, and optimizing analytics to empower research. My interest in data began in my undergraduate career, where I built a strong foundation in analytics through my studies in chemistry, geology, and ecology. Towards the end of my degree, I took a computer science course on a whim and was immediately hooked. Ever since, I've been studying it in my spare time.
What started as a hobby led into positions as an analyst in soil logistics, then as a scientist in the data solutions department of an environmental consulting firm. From there, I decided to pursue a Masters of computer science at Georgia Tech to quench my thirst for knowledge and develop a formal education in the field. The rest is history!